
Pandas 名字衍生自术语 “panel data”(面板数据)和 “Python data analysis”,一 个强大的分析结构化数据的工具集,基础是 Numpy,可以从各种文件格式比如 CSV、SQL、 Excel 导入数据,对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数 据加工特征。Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。Pandas 的主要 数据结构是 Series (一维数据)与 DataFrame(二维数据)
Series对象
Series 是一个一维数据,Pandas 会默认用 0 到 n-1 来作为 Series 的 index, 但也可以自己 指定 index(可以把 index 理解为 dict 里面的 key)
1 | pandas.Series( data, index, dtype, name, copy) |
参数说明:
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从 0 开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
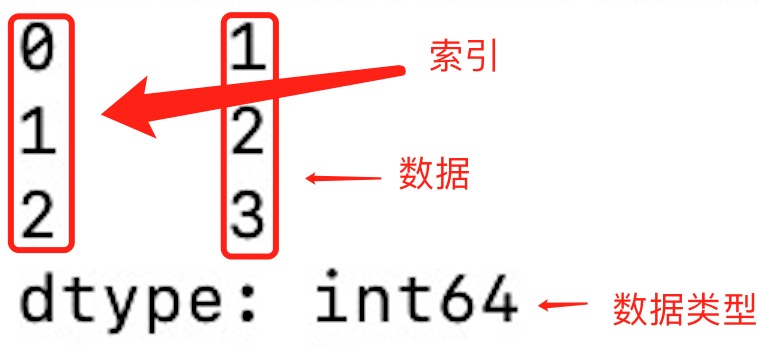
切片
data为字典
默认根据字典的键码字符串顺序排序,也可以设定顺序。
1 | s = {"ton": 20, "mary": 18, "jack": 19, "car": None} |
Pandas数据框(DataFrame)
1 | pandas.DataFrame( data, index, columns, dtype, copy) |
参数说明:
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
1 | # Pandas数据框 |
对 DataFrame 对象增加列
1 | df["rich"]=df["cash"]>200 |
1 | ## 指定列的顺序 |
数据框索引
①iloc 主要使用数字来索引数据,而不能使用字符型的标签来索引数据。而 loc 则刚好 相反,只能使用字符型标签来索引数据,不能使用数字来索引数据。注意:数字索引范围不 包括结尾,而字符索引范围包括结尾。
②ix 是一种混合索引,字符型标签和整型数据索引都可以。
1 | ## 数据引用 |
数据清洗
删除空值的行/列
语法格式
1 | DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) |
参数详解
axis:轴。0或’index’,表示按行删除;1或’columns’,表示按列删除。
how:筛选方式。‘any’,表示该行/列只要有一个以上的空值,就删除该行/列;‘all’,表示该行/列全部都为空值,就删除该行/列。
thresh:非空元素最低数量。int型,默认为None。如果该行/列中,非空元素数量小于这个值,就删除该行/列。
subset:子集。列表,元素为行或者列的索引。如果axis=0或者‘index’,subset中元素为列的索引;如果axis=1或者‘column’,subset中元素为行的索引。由subset限制的子区域,是判断是否删除该行/列的条件判断区域。
inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。
案例
1 | import pandas as pd |
填充空值
语法结构
1 | DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs) |
参数详解
- value: 变量、字典、Series,DataFrame;用于填充填充缺失值,或指定为每个索引(对于Series)或列(对于DataFrame)的缺失值使用字典/Series/DataFrame的值填充
- method: {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, 默认None, pad/ffill表示向后填充空值,backfill/bfill表示向前填充空值
- axis: {0 or ‘index’, 1 or ‘columns’}
- inplace: boolean, 默认为False。若为True, 在原地填满
- limit: int, 默认为None, 如果指定了方法, 则这是连续的NaN值的前向/后向填充的最大数量
- downcast: dict, 默认None, 字典中的项为类型向下转换规则。
案例
1 | x=round(df['age'].mean(),2) |
转换列的日期格式
语法格式
1 | pandas.to_datetime(param, format="") |
参数详解
案例
1 | ## 处理日期(字符转换为日期) |
删除空行后重置索引
reset_index()函数
1 | df.reset_index(drop=True) |
箱线图Keyvalue:0报错
原因可能就是去除了空值,去除了index=0的元素,这个时候将索引重置就可以解决问题
分组汇总
groupby()核心用法总结
- 根据DataFrame本身的某一列或多列内容进行分组聚合:
(a)若按某一列聚合,则新DataFrame将根据某一列的内容分为不同的维度进行拆解,同时将同一维度的再进行聚合,
(b)若按某多列聚合,则新DataFrame将是多列之间维度的笛卡尔积,即:新DataFrame具有一个层次化索引(由唯一的键对组成),例如:“key1”列,有a和b两个维度,而“key2”有one和two两个维度,则按“key1”列和“key2”聚合之后,新DataFrame将有四个group;
(c)通过调用get_group()函数可以返回一个按照分组得到的DataFrame对象,该对象是分组中的一种情况;
(d)可以将想要计算的列(可以是单列,也可以是多列)通过索引的方式取出来,然后在取出来这列数据的基础上进行汇总计算。eg:df.groupby(“状态”)[“区”]、df.groupby(“状态”)[[“区”,“省”]]
注意:groupby默认是在axis=0上进行分组的,通过设置axis=1,也可以在其他任何轴上进行分组。
- GroupBy对象结合描述统计方法从各个分组中产生标量值:
(a)这个标量值可以是平均值、数量、中位数等。GroupBy对象常用的描述性统计方法如下表所示:
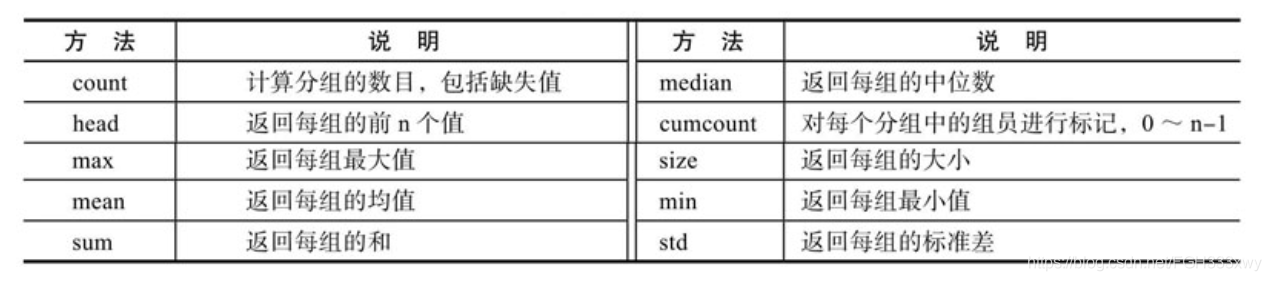
普通过滤
分组过滤
 Wechat
Wechat- Alipay





